Transactions help manage the conflict that arises when multiple requests must simultaneously access and update the same data. But this is not the only way to avoid data conflict.
Consider a simple counter of the number of ‘likes’ on a social media post. Increasing the counter might involve the following three operations:
-
Read the current count from the database (Read x)
-
Add one to the count (Compute x' = x + 1)
-
Save the updated count to the database (Write x')
In the section on concurrency, I explained how likes could be lost when processing concurrent requests.
One way to eliminate data conflict and the need for transactions is to remove all update operations. For example, instead of counting the number of likes, the system could record the users that like the post. The revised algorithm has just one step:
-
Record the current user (Write user likes x)
For example, suppose Alice, Bobby and Carol like a post, x, they each add themselves:
|
Timestep |
Alice |
Bobby |
Carol |
|---|---|---|---|
|
1 |
Write { alice likes x } |
||
|
2 |
Write { bobby likes x } |
Write { bobby likes x } |
In the end, the system will have accumulated three values: { alice likes x, bobby likes x, carol likes x }. The system can calculate the total number of likes of the post x by counting the users who liked x (i.e., 3 users). [1] This is a conflict-free data structure: the ‘like’ operation does not have the possibility of conflict.
An intuitive way to understand why this helps is to think about how to update a count using pen-and-paper. It is easy to see that only a single person can cross-out and update numbers. However, several people can simultaneously add tally marks to different parts of the same page, without interference. The left-hand side of the image below almost certainly was updated one-at-a-time. However, on the right-hand side, several pens could have been used to simultaneously mark the eleven tallies.
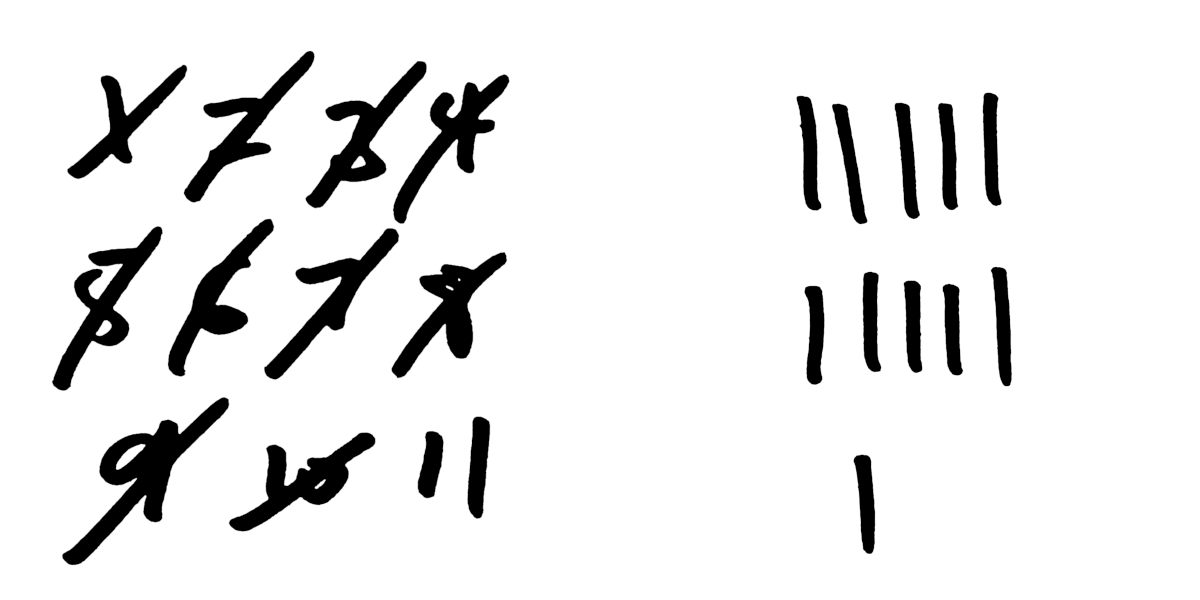
This representation eliminates potential conflicts from concurrent updates. However, there is a penalty to pay. This representation must keep track of individual users. Also, the total requires a query, rather than reading a single numerical value.
Immutability, idempotency and monotonicity
Transforming a numerical count of ‘likes’ into a set of the specific ‘likes’ has eliminated the need to update data. Other problems also benefit from this kind of transformation.
Most concurrency problems arise when updating data. Translating the data so that it does not need to be updated may eliminate the need for transactions. [2]
Then, how do we write useful programs that don’t perform updates?
There are four important ideas to consider:
- Immutability
-
In computer science, an immutable object is an object that does not change. For example, in JavaScript, strings are said to be immutable because a string cannot be modified. Concatenating text to the end of a string in JavaScript does not change the original string. Instead, it creates an entirely new string.
You can create immutable objects in any code by never modifying an object or value. Instead, create a new object that includes the changed values.
For example, compare a mutable vs immutable update in the following JavaScript: [3]
// Original object let b = { name: "Bobby", age: 13 }; // Mutable update: updates the original object b.age = 14; // Immutable update: creates a new object based on a copy of b let b2 = {...b, age: b.age + 1};A persistence layer can provide immutability by inserting new rows into a table, rather than updating existing rows. The latest version of a row can be identified by adding a column for the modification date or version.
- Idempotency
-
In mathematics, an idempotent function is one in which repeated application produces the same result. For example, the absolute value function produces the same result irrespective of how many times it is used: abs(x) = abs(abs(x)) = abs(abs(abs(x))).
In JavaScript, an idempotent function does not produce an incorrect state if called repeatedly. For example, to keep track of social network ‘likes’, when a user clicks on the like button, it would not be an idempotent operation to just record that an extra ‘like’ has occurred. Instead, by storing the specific users that ‘liked’ a post, duplicates can be safely ignored.
- Monotonicity
-
In mathematics and formal logic, a monotonic operation only moves in one direction: if it increases, it never reverses. For example, mathematical knowledge is monotonic: a mathematical proof discovered today will be true forever (2 + 2 = 4 is true today, and will never become untrue). [4]
You can create monotonic data structures by ensuring that changes only occur in one ‘direction’. For example, if you only add to a set or only append to a list (never remove).
- Associativity
-
In mathematics, associativity refers to the idea that the order of operations does not matter. For example, addition of x, y and z is associative: ( x + y ) + z = x + ( y + z ). It does not matter whether if you add x and y are first, or y and z first. The result is the same.
In your code, you can use associative data structures do not care about the order of updates. Examples of associative operations include the associative mathematical operations (multiplication, addition), adding to a set, adding to a sorted list, and bit-setting on an integer.
These four ideas (immutability, idempotency, monotonicity and associativity) underpin safe data structures. For example, if every operation on a network is idempotent, then there is no danger of corruption if messages are accidentally resent. If every object is immutable, then there is no need to worry about whether an object needs to be modified. If every operation is monotonic, there is no need to worry about whether replaying or reordering messages will result in data loss. If every operation is associative, it does not matter if the system delivers messages in an incorrect order.
CRDT
Conflict-free replicated data types (CRDT) use immutability, idempotency, monotonicity and associativity to allow safe updates without transactions.
The grow-only set is perhaps the easiest CRDT to understand. A grow only set is an unordered collection that allows elements to be inserted or queried (no deletion or update) and that ignores duplicates.
-
The individual elements are immutable: they do not change.
-
Both insertion and querying are idempotent: duplicated insertions are equivalent to inserting a value just once. Querying does not change the set.
-
Insertion grows the set monotonically. The set does not permit removal.
-
The order of insertion is irrelevant: the result of any sequence of insertions is the same.
JavaScript has had a Set object since 2015. However, the keys of an object may also simulate a set:
let likes = {};
function like(username) {
likes[username] = true;
}
function countLikes(username) {
return Object.keys(likes).length;
}In a distributed system, every server can maintain a separate grow-only set. Given regular synchronization (e.g., sending insert notifications to other sites), the system will converge to the correct final state.
For example, ‘likes’ from an external server can be synchronized with the local set of ‘likes’ using code such as the following:
function synchronize(otherLikes) {
for (let key in otherLikes) {
likes[otherLikes] = true;
}
}As long as all the servers regularly synchronize with each other, inserted items will eventually reach all servers. Because the grow-only set is monotonic and commutative, every server will end up with the same ‘likes’. This convergence is known as eventual consistency because every server in a system will eventually reach the same final data.
NoSQL databases and collaborative editors make extensive use of CRDTs. NoSQL databases that use CRDTs to ensure consistency include Redis and Riak. If you would like to build a collaborative editor (e.g., an editor like Google Docs), libraries such as Yjs provide document-based CRDTs for you to embed in your code. [5]
Tombstoning
Monotonicity may seem to be an unreasonable constraint. Sometimes data needs to be deleted. For example, if a user accidentally ‘liked’ a post but now wants to ‘unlike’ it.
Tombstoning is a solution to this dilemma. Instead of removing unwanted data, a ‘tombstone’ is a signal to hide earlier data. [6]
For example, suppose we have a grow-only set representing three users who liked a post:
-
Initially, the set contains { alice, bobby, carol }
-
The tombstone deleted(bobby) is added when Bobby ‘unlikes’ the post
-
The result has four elements: { alice, bobby, carol, deleted(bobby) }
When end-users view the number of likes, they see the entries that do not have tombstones (i.e., Alice and Carol).
The tombstone takes precedence and is permanent. This rule preserves idempotency and associativity. Adding bobby again does not override the tombstone. Adding a tombstone deleted(greg), hides greg forever, even if Greg likes the post after the system creates the tombstone.
The idea behind this technique is useful even in database design for transactional systems. For example, if a user creates a shared document, there will typically be a relationship between the document and that original creator. If the user later deletes their account or stops paying for a subscription, it can be difficult to delete the user account while retaining the documents. It is often easier to add a boolean isDeleted column to the user table. Instead of deleting the record, set the isDeleted column to true. [7]
Clocks
The idea behind serializability is that operations are equivalent to some serial execution. Serializability helps in situations where there is a need to decide whether one operation happened before another. Systems that use CRDTs without transactions may require an alternative scheme for ordering operations.
Unfortunately, computer clocks are not good enough. Computer clocks can be wrong in many ways:
-
They may have an incorrect date/time
-
They may have an incorrect timezone
-
They can change at different speeds (some clocks run slightly fast, others run slow, some will alternate between being too fast or too slow)
-
They don’t increment consistently (e.g., the time of the low-resolution clock on IBM-compatible PCs only increases 18.2 times a second, though modern operating systems provide higher resolution timers with millisecond or microsecond accuracy)
-
They can suddenly jump forwards or backward in time (e.g., when the clock gets set)
Even if computer clocks could be made perfect, the laws of physics dictate that event ordering is relative. According to the special theory of relativity, whether two events occurred simultaneously depends on the observer’s position. Special relativity is not just a theoretical problem: computers perform hundreds of calculations in the time it takes for light to travel across a data-center or even a room. A server ‘observing’ other computers from one side of a data center will see a different ordering of events than an observer standing on the other side of a data center.
Lamport clocks are one way to establish a consistent serial ordering of events between processes or servers.
A Lamport clock does not keep track of the usual time measured by a watch or wall clock. It is a logical clock that provides nothing more than a number that monotonically increases. It may slow down, speed up and jump suddenly.
Each process or server, i, retains a version of the Lamport time Ci. The clock updates according to the following rules:
-
Increment the clock whenever an event happens (i.e., Ci' = Ci + 1)
-
Regularly send clock’s current value to other servers/processes (e.g., it can be included in every message)
-
On receipt of a remote server’s clock, update the local clock to the maximum of the local value and remote value (i.e., Ci' = max(Ci, Cj) )
The Lamport time Ci provides an ordering of events. Whenever two events occur at the same Lamport time, a unique number of each process (i) can serve as a tie-breaker. [8]