What happens when you entered https://localhost:8080/ into your web browser to view the pages served by Express? Many steps must occur for your browser to translate the URL into a web page on your screen.
You do not need to undestand all these steps to build a website. However, an understanding of these steps will help you debug your code and write more efficient, secure, responsive and scalable websites.
One way to understand this problem is by thinking about layers.
I will explain, in detail, these layers:
|
Rendering engine |
|
|
Browser engine |
|
|
HTTP |
|
|
TCP |
DNS |
|
UDP |
|
|
IP |
|
Notice that each layer depends on the service provided by the layer below.
Your web browser handles the first three layers (rendering engine, browser engine and HTTP). Your operating system (e.g., Linux / Windows / macOS / iOS / Android) typically handles the remainder.
Rendering engine
The first layer to consider is the rendering engine. It is responsible for creating the images that appear on your screen. It ensures that the shape of each letter in a web page appears in the correct font, location and color on the screen.
Our HTML document has a structure that is something like this:
|
Content-Type |
text/html (an HTML document) |
|
|
Title |
Hello, World! |
|
|
Body |
Heading 1 |
AIP |
|
Paragraph |
Hello, World! |
|
The rendering engine will set the title of the browser window with the document’s title. After that, it will use its built-in styles to understand how to format level-1 headings and paragraphs. For example, my web browser associates h1 with a font named DejaVu Serif Bold and a height of 32 pixels on the screen. It associates p with a font named DejaVu Serif and a height of 16 pixels on the screen (CSS can override these defaults).
The rendering engine communicates with your operating system to load the fonts, calculate the size of the text, and draw the individual characters on the screen.
The rendering engine can render many types of documents. For example, if the document includes images format, then it will make operating system calls to draw the image on the screen. If it is a video, then it will show the frames of the video.
For all this to happen, the rendering engine needs a way to be able to retrieve the structured HTML document using a URL.
Browser engine
The browser engine is responsible for retrieving structured documents from a URL.
When you enter a URL (e.g., http://localhost:8080/) into your browser window, the browser engine is responsible for creating a request and interpreting the response.
A request might look something like this:
|
Method |
GET / |
|
|
Headers |
Accept |
text/html |
|
Accept-Language |
en |
|
|
User-Agent |
Mozilla/5.0 Firefox/100.0 |
|
|
Body |
(none) |
|
The browser engine will use the HTTP layer to send this request to the server and then receive a response that is something like this:
|
Status |
200 |
|
|
Headers |
Content-Type |
text/html |
|
Content-Length |
78 bytes |
|
|
Date |
Monday, 1 January … |
|
|
Body |
<!DOCTYPE html> <title>Hello, World!</title> <h1>AIP</h1> <p>Hello, World!</p> |
|
The method, headers and status are all used to provide information about the request and response.
In the request, they tell the server what kind of document you want to see. For example, an English (en) document in HTML format (text/html) suitable for the Firefox browser.
In the response, the headers describe the value that is returned. For example, that the body is in HTML format (text/html), 78 bytes long, and was generated on 1 January.
The browser engine understands that when it sees the ‘text/html’ content-type, that it needs to parse the body as an HTML document. Parsing means that the engine will recognize the structure of the data:
-
It tokenizes the document (
<!DOCTYPE html>,<title>,Hello, World!,</title>,<h1>,AIP,</h1>,<p>,Hello, World!,</p>) -
Then, it matches the tokens for the opening and closing tags, to recognize elements: (a
titleelement containing “Hello, World!”, ah1element containing “AIP”, apelement containing “Hello, World!`”) -
Finally, it constructs a structured document for the rendering engine
|
Tip
|
The Content-Type might have been something other than text/html. For example, if the content type is image/jpeg then the browser engine will expect the body of the response to be the binary data for a JPEG image. |
|
Tip
|
The Method in the request is used to indicate the operation to perform on the URL. When you retrieve a document, your browser engine will use the “GET” method. When you submit a form, your browser engine will use the “POST” method. Other common method names are “OPTIONS”, “HEAD”, “PUT”, “DELETE”, “TRACE”, “CONNECT”. However, a web server can support any sequence of characters (except separators) as a valid method name. |
|
Tip
|
The browser keeps track of previous requests using internal storage, called a cache. If you request the same document multiple times, the browser engine might decide to return the previously saved version rather than make a new request. |
|
Tip
|
The Status in the response tells the browser engine whether the request was successful. A status of 200 means that your request succeeded. You may already know 404 as the server reporting that the document could not be found. However, there are numerous status codes for conditions including information (100-199), success (200-299), redirection (300-399), client errors (400-499) and server errors (500-599). |
For all this to happen, the browser engine needs a way to be able to send a request and then retrieve a server response from a URL.
HTTP
HTTP, or Hyper-Text Transfer Protocol, is a standard way of encoding requests and responses for transmission over the internet. This layer is responsible for taking the request and headers, and encoding them in a consistent format for data transmission.
HTTP is a simple text-based protocol.
Suppose you wish to perform a GET request to the URL http://localhost:8080/, the HTTP standard states that this request can be encoded into a single steam of text as follows:
GET / HTTP/1.1 Host: localhost Accept: text/html Accept-Language: en User-Agent: Mozilla/5.0 Firefox/100.0
This information will get sent to the server, and then the server will generate a response that might be encoded using HTTP as follows:
HTTP/1.1 200 OK X-Powered-By: Express Content-Type: text/html; charset=utf-8 Content-Length: 78 Date: Sat, 01 Jan 2000 10:20:30 GMT Connection: keep-alive <!DOCTYPE html> <title>Hello, World!</title> <h1>AIP</h1> <p>Hello, World!</p>
|
Tip
|
You can see the internals of the HTTP request/response using your web browser’s development tools. In most browsers, these are called "Developer Tools" or "Web Developer" and are accessible through the browser’s menu or by pressing Control+Shift+I or Command+Option+I. The Network tab will show information about every HTTP request, and you can see the exact headers sent and received in each request. |
|
Tip
|
You will see many additional headers in a real request to a real server. I suggest you visit a range of mainstream websites to see how the requests and responses vary. |
|
Tip
|
The server can optimize its response based on your request. For example, if your Accept-Language is fr, then it could return a French version of the page (if one is available). |
|
Tip
|
The examples above use HTTP/1.1 (i.e., version 1.1 of HTTP). However, there are newer versions. HTTP/2 and HTTP/3 are growing in popularity. However, they are 100% backwards compatible with HTTP/1.1. They have exactly the same concepts but use a more complicated encoding for more efficient communication and to allow multiple simultaneous requests over a single connection. |
|
Tip
|
Header names are not case-sensitive. “Content-Type” is the same as “Content-type” and “content-type”. In fact, in HTTP/2 and HTTP/3, headers must be transmitted in lowercase. |
For all this to happen, two things are required:
-
a way to find the IP address of a server, given its name (i.e., DNS);
-
a way to send and receive encoded HTTP data to/from the IP address of a server (i.e., TCP).
DNS
DNS, or the Domain Name System, is responsible for translating names into IP addresses.
When you lookup localhost, your computer checks in the hosts file for an IP address (Linux: /etc/hosts, Mac: /private/etc/hosts, Windows: C:\Windows\System32\drivers\etc\hosts). Localhost will normally resolve to 127.0.0.1 which is always an IP address of the local computer.
[1]
You can manually add any name to the hosts file. In the early days of the internet, there was no DNS and system administrators would share hosts files manually. These files became too large and too hard to manage, so DNS was created.
If a name is not in the hosts file, a DNS resolution process will begin.
DNS has 13 root servers at predefined IP addresses (198.41.0.4, 199.9.14.201, 192.33.4.12, 199.7.91.13, 192.203.230.10, 192.5.5.241, 192.112.36.4, 198.97.190.53, 192.36.148.17, 192.58.128.30, 193.0.14.129, 199.7.83.42, 202.12.27.33).
Suppose you wish to lookup aws.amazon.com. The name lookup will begin with a root server. A message is sent to one of the root servers to request the IP address for aws.amazon.com. The root servers do not know the answer for this query, but they respond with the IP addresses for the top-level domain servers that handle .com domains. Next, a message is sent to the .com DNS servers which will, in turn, give you the IP addresses for the name servers that can handle amazon.com requests. This process repeats for amazon.com until finally, Amazons’s DNS servers tell you the IP address for aws.amazon.com.
|
Tip
|
If this process happened on every single DNS lookup, the name resolution process would be extremely slow. Every request would require contacting numerous DNS servers. The root servers would be overloaded, needing to resolve every single name. Instead, caching is used to speed up requests. For example, if you have already resolved aws.amazon.com, then you can start resolving www.amazon.com from amazon.com (rather than the root nameservers). Furthermore, your internet service provider or workplace will run their own DNS server that will cache requests across users. If you lookup aws.amazon.com, your internet service provider can reuse the answer it found when it resolved that name for your other users.
|
The DNS standards define the format of the query and response messages. Normally, DNS messages are sent using UDP on port 53, but DNS will use TCP for large requests or responses. There is also an emerging standard that allows DNS requests to be performed over HTTP/HTTPS.
For a name lookup to happen, the DNS resolver needs a way to be able to send short messages over the internet.
UDP
UDP, or User Datagram Protocol, is a way of encoding messages for transmission over the internet.
UDP is an very simple mechanism to allow multiple applications to send short messages over the internet. UDP combines a message (supplied by a higher layer), with four pieces of information:
-
Source port (a 16-bit number identifing the source application)
-
Destination port (a 16-bit number identifying the destination application)
-
Length of message
-
Checksum (a value used to check whether the data has been transmitted without corruption)
UDP uses port numbers to send messages to the correct application. For example, Windows Remote Desktop uses UDP port 3389, L2TP virtual private networks use UDP port 1701, the STUN/TURN protocols used for peer-to-peer video conferencing on the web use UDP port 3478. Most important for our discussion is that DNS uses UDP destination port 53. The destination port for DNS (i.e., port 53) is standardized by IANA, the Internet Assigned Numbers Authority.
|
Tip
|
UDP does not attempt to provide any reliability guarantees. If a message is lost during transmission, it will not be automatically retransmitted. This means that higher-level applications need to manually handle retries. [2] |
UDP provides a way of ensuring messages reach the correct applications, however it depends on a way to send messages to other computers on a network. This lower layer capability is provided by the IP layer. I will momentarily digress to cover TCP, which provides the data streams used by HTTP.
TCP
TCP, or Transmission Control Protocol, is a way of sending streams of data over the internet.
A data stream is a potentially endless series of bytes. A data stream is a connection that allows bytes to be written from one computer, which are then forwarded so that they can be read from another computer.
TCP differs from UDP in two ways:
-
TCP can send an unlimited stream of bytes of data in order, whereas UDP sends messages
-
TCP uses retransmission to provide a more reliable service, whereas UDP does not resend lost messages
-
TCP uses sequence numbers so that data is received in the same order it is sent, whereas UDP provides no ordering guarantees
TCP works by breaking up the data stream into shorter packets that can be sent as separate messages. In each message, TCP adds extra information so that it can automatically handle resending and reordering:
-
Source port (like UDP, a 16-bit number used to identify the source application)
-
Destination port (like UDP, a 16-bit number used to identify the destination application)
-
Sequence number (a number that increases with each message, used to reconstruct the data stream in the correct order)
-
Acknowledgement number (a number that informs the sender which packets have been received and that do not need to be resent, and what the receiver is expecting next)
-
Control flags (used to open and close the connection)
-
Window size (used to coordinate the amount of data being sent at once)
-
Checksum (a value used to check whether the data has been transmitted without corruption)
TCP uses a complex flow-control algorithm to adapt to connections. On bad connections it will resend lost messages and slow down. On good connections it will speed up.
Like UDP, established conventions dictate what services should be run on different destination ports. For example, HTTP connections are typically served on TCP port 80 and HTTPS (SSL/TLS) connections are typically served on TCP port 443 (other common services include FTP on TCP port 21 and SSH on TCP port 23).
In an HTTP request, the default port can be overriden by the URL. For example:
-
An HTTP request to http://localhost/ will use the default of TCP port 80 to connect to localhost
-
A secure HTTP request to https://localhost/ will use the of TCP port 443 to connect to localhost
-
The “:8080” that appears in a URL such as http://localhost:8080/, means that the HTTP request will use TCP port 8080 to connect to localhost
|
Tip
|
To establish the TCP connection, a “3-way” handshake is involved in the set up. This requires, at a minimum, a full round-trip before any data can be sent:
This handshake is needed to avoid duplicate connections and avoid spoofing. A consequence is that the setup process can be slow. It takes 70 milliseconds for light to travel from Sydney to Silicon Valley in fiber-optic cable. Thus, the laws of physics mean that it takes at least 210 milliseconds to complete the full handshake before the first byte of data in a TCP connection will be received in Silicon Valley. |
|
Tip
|
Secure HTTP requests (HTTPS) use a protocol called TLS or Transport Layer Security. TLS is an intermediate layer that depends on TCP: it enhances an ordinary TCP connection with encryption so that eavesdroppers cannot intercept messages. |
Finally, for TCP and UDP to work, they depend on an ability to send messages between computers on the internet.
IP
IP, or Internet Protocol, is the underlying protocol that defines the internet.
Each computer on the internet has at least one unique number known as an IP address. The internet protocol allows two computers with IP addresses to send messages (or packets) to each other.
The internet protocol adds its own headers to each message:
-
Length (the total length of the message)
-
Identifier and fragment offset (used to indicate if the message has been broken up into small parts during transmission)
-
Time to live (how long the message can last for before being discarded)
-
Protocol (whether the message is TCP, UDP or another protocol)
-
Checksum
-
Source computer’s IP address
-
Destination computer’s IP address
IP provides no guarantees. When a message is sent by IP it could be lost, duplicated or even fragmented during transmission.
Routers are responsible for passing packets from the source to the destination. For example, suppose my computer has IP address 198.51.100.12 and it is sending a message to a server with IP address 203.0.113.55 located in Los Angeles. First, my computer will pass the message to the local router at 198.51.100.1. The router will recognize that the destination isn’t local, so it will pass it on to a router in a Telstra data center. The Telstra router may not know exact location of the destination computer from its IP address, but it might know that all 203.x.x.x computers are in the USA, so it will pass along the message to the next router that is slightly closer to the destination. This continues step-by-step, with each router only needing to know how to get the message a little bit closer, until eventually the packet reaches its destination.
|
Tip
|
The fact that IP provides no guarantees helps ensure the internet is simple and scalable. Routers do not need to keep track of connections. If routers get overloaded with data, they can randomly drop messages. They can drop messages for being too large. They don’t have to worry about accidentally losing data or resending data because if anything goes wrong, the higher level layers are supposed to adapt to it. |
|
Tip
|
The world has run out of IP addresses and so they need to be conserved. For this reason, your network at home might use Network Address Translation (NAT) so that multiple devices can share a single IP address. If your local network is doing NAT then your IP address will typically be between 10.0.0.0 and 10.255.255.255 or between 172.16.0.0 and 172.31.255.255 or between 192.168.0.0 and 192.168.255.255. Your router will silently translate all the local IP addresses into a single real IP address that will be used to communicate with the rest of the internet. |
I’ve reached the bottom layer for the purposes of this discussion. However, in practice IP relies on lower link-level layers. IP needs an ability to send messages across individual links (e.g., through the Ethernet cable that is plugged into your computer, or by radio signalling from your laptop to the nearest WiFi router).
Discussion
We’ve covered a great deal of detail here. Don’t be concerned if you didn’t understand every detail in this discussion. The key point is that you should look at the big picture and understand the layering:
-
The final, lowest layer (IP) is very simple. Higher layers (e.g., TCP, UDP, DNS, HTTP, Browser engine) build upon the lower level layers to add increasing levels of sophistication and meaning: reliable connections, name services, security, HTML document requests.
-
The layering allows for an extraordinary increase in complexity. IP is concerned with small packets of unstructured binary data, whereas rendering engines are concerned with multi-lingual documents and images with rich formatting.
-
Layering makes it possible for the internet to handle billions of users at the same time. Routers only need to understand IP and know how to forward each packet, so they can focus on speed and do not need much memory. Your operating system deals with managing connections (TCP, UDP) so it can focus on reliability and security. Your web browser is responsible for making sense of the data, so it can use your computer’s CPU and memory to render complex text, images and video without placing any burden on the intermediate networks.
-
Layering allows for more rapid evolution and improvement of technology. Your web browser does not need to be upgraded to support WiFi or Powerline Ethernet or 5G mobile networks. Similarly, your internet service provider does not need to upgrade their network when you start using DNS over HTTP or websites that use HTTP/2 or HTTP/3 instead of HTTP/1.1. Each layer can evolve independently, as long as it keeps its internal details hidden from the other layers.
Layering is one of the most powerful concepts in computing and internet programming. However, every benefit has trade-offs. What might be some disadvantages of this layering in internet programming?
|
Tip
|
Many aspects of the layering appear to be arbitrary and without explanation (e.g., why was port 80 chosen for HTTP, port 53 for DNS and 443 for SSL/TLS?). This may be confusing if you like everything to have an explanation. Instead, it helps to understand the layering used today as an outcome of a historical process. For example, ports were chosen for protocols on the basis that the port number was not already in use when the protocol was invented. Many aspects of HTTP and TCP/IP are not ideal: if the internet were to be redesigned from scratch today, it would be very different. [3] |
Reflection questions
Think about how layering can solve or explain the following situations:
-
When you visit https://www.linkedin.com/, you see an English website but when your French-speaking friend goes to the same website, they see French text. How does the website know?
-
You are running a web server on port 8080 but when you enter http://localhost/ into your browser, it says “Unable to connect”. Why not?
-
You are running a web server on your local computer (whose IP address is 10.0.0.3), but your friend in another city can’t see it when they enter http://10.0.0.3/ into their browser. Why not?
-
You have set up a server on a public IP address 203.0.113.55. You can see your site when you visit http://203.0.113.55/ but nothing appears when you use the domain name that you recently purchased: http://www.your-organization.com/. Which layer is likely to be the cause of this problem? What might you do to fix it?
-
You run the following code on your web server (it is the same code as earlier, but it explicitly sets a content-type header):
const express = require('express'); const app = express(); function indexHandler(request, response) { response.set('Content-Type', 'text/plain'); response.send(`<!DOCTYPE html> <title>Hello, World!</title> <h1>AIP</h1> <p>Hello, World!</p>`); } app.get('/', indexHandler); console.log('Running on http://localhost:8080/'); app.listen(8080);When you open the code in a web browser, why does it render the code as depicted below, instead of a properly rendered HTML page with bold text and formatting?
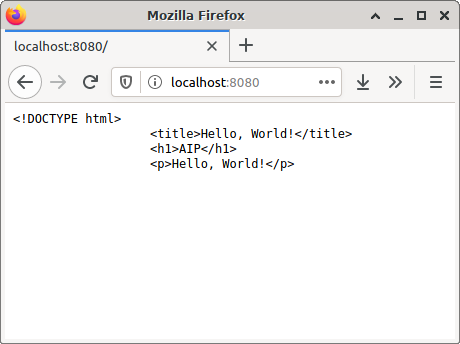
-
Suppose you are not allowed to use Facebook at work, but you carefully use a secure HTTPS request (https://www.facebook.com/) to ensure that the connection is encrypted. However, your employer fires you for using Facebook during business hours. How might they have figured out that you were using Facebook?
-
Why might a web page load faster when you visit it a second time in the same day? (There could be lots of reasons — think of as many as you can!)
-
If you had the power to completely replace the internet with a ‘new and improved internet’, what changes would you make? In other words, how might you redesign the layering and the technologies of the internet, if you could?