Computer science has a long tradition of exploring sorting algorithms including the absurd bogosort to the surprising ICan'tBelieveItCanSort. In that tradition, how well does an LLM perform as a sort algorithm?
I generated random samples of n unique words from the Unix/Linux wordlist (/etc/share/dict/words), then passed the words to an LLM, with a system prompt requesting the LLM return the same words sorted into the correct order.
To avoid potential confusion about sort ordering and case, I only used lowercase ASCII alphabetic words (i.e., words matching the regular expression ^[a-z]+$). For a given input length, I tested the LLM 100 times, with a different random sample in each test.
I used the following system prompt:
Sort the following words into alphabetical order (US English ASCII order). Return only the sorted words, separated by newline characters. Do not include any other words or commentary. Return the words exactly-as is. Do not change their spelling, case or punctuation. If no input is provided, then return an empty result.
I post-processed the LLM output by splitting the result on newlines and removing whitespace.
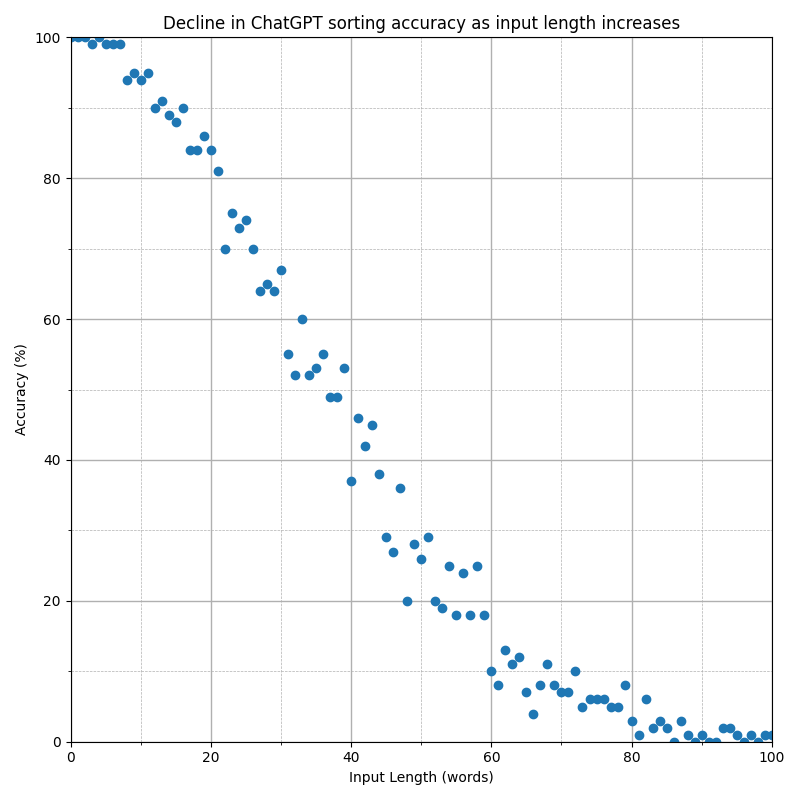
The following is a plot of the accuracy at different input lengths, for OpenAI's gpt-4o model:
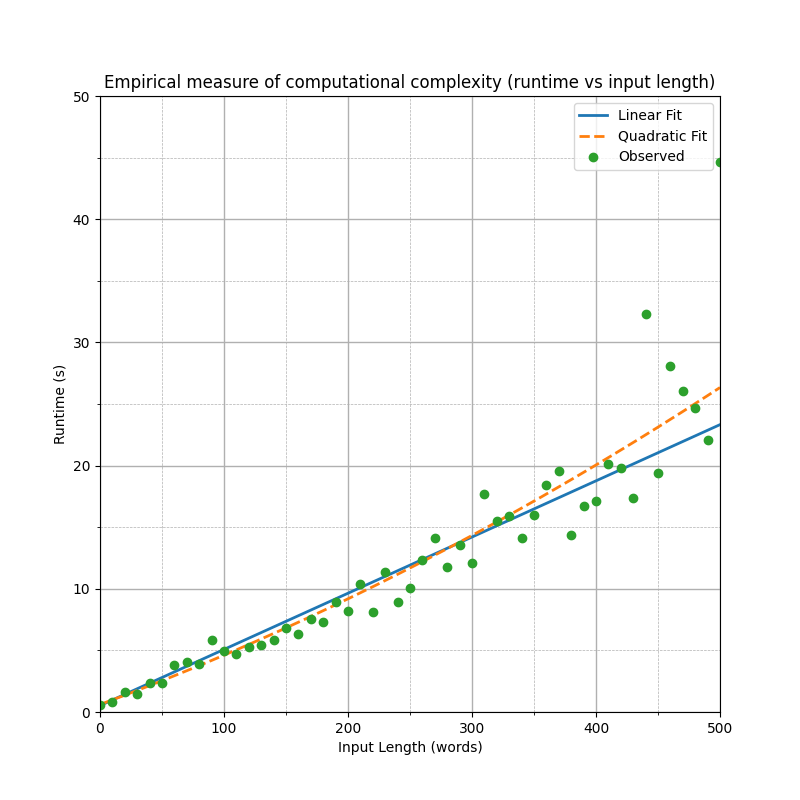
As for the computational complexity, my understanding is that the underlying LLM is O(n) in the input length, for a single output token, and therefore at least O(n2) to sort a list. The empirical data suggests that the linear component dominates, especially with shorter lists. I expect this is because the overheads of the fixed system message and iteration dominate the runtime. Running more tests with lists of up to 500 words, there isn't a clear line of best fit. However, a quadratic fit is better, even after penalizing for the complexity by the Akaike Information Criterion. (Note: these fits assume Gamma error because runtime is not normally distributed and standard linear regression results in a very poor fit).
To conclude, LLM sort is only reliable for up to two words, and is correct 50% of the time with approximately 36 words. For 500 words, 0% accuracy comes with a run time that is 430,000 times slower than Python sorted and roughly $0.027 per sort (roughly 10,000,000 times more expensive than running Python in the cloud). This makes it perfect for those situations where you have too much money and don't care about results!